Below you will find pages that utilize the taxonomy term “Scheudle”
📎Posts
vllm 异步调度解析
在vllm初始版本中只有一个同步调度策略,在该策略下GPU资源会在调度过程中形成空泡,造成GPU资源的浪费。vllm在v0.10.0版本后提供异步调度策略,并且在后续的迭代中不断加入对于其他特性(例如异步场景下的投机解码)的支持。原始PR内容可查看#19970 Implement Async Scheduling ,当前代码分析基于main branch(735284ed)。
EngineCore处理处理Step逻辑:
def _process_engine_step(self) -> bool:
"""Called only when there are unfinished local requests."""
# Step the engine core.
outputs, model_executed = self.step_fn()
# Put EngineCoreOutputs into the output queue.
for output in outputs.items() if outputs else ():
self.output_queue.put_nowait(output)
# Post-step hook.
self.post_step(model_executed)
return model_executed
同步调度策略#
def step(self) -> tuple[dict[int, EngineCoreOutputs], bool]:
if not self.scheduler.has_requests():
return {}, False
scheduler_output = self.scheduler.schedule()
# 通过FutureWrapper进行异步包装(复用异步调度的部分逻辑, 在同步调度逻辑里面会等待结果返回)
#
future = self.model_executor.execute_model(scheduler_output, non_block=True)
# 用于支持结构化输出等
grammar_output = self.scheduler.get_grammar_bitmask(scheduler_output)
with self.log_error_detail(scheduler_output):
# 同步
model_output = future.result()
if model_output is None:
model_output = self.model_executor.sample_tokens(grammar_output)
# 处理整个过程中abort的请求
self._process_aborts_queue()
engine_core_outputs = self.scheduler.update_from_output(
scheduler_output, model_output
)
return engine_core_outputs, scheduler_output.total_num_scheduled_tokens > 0
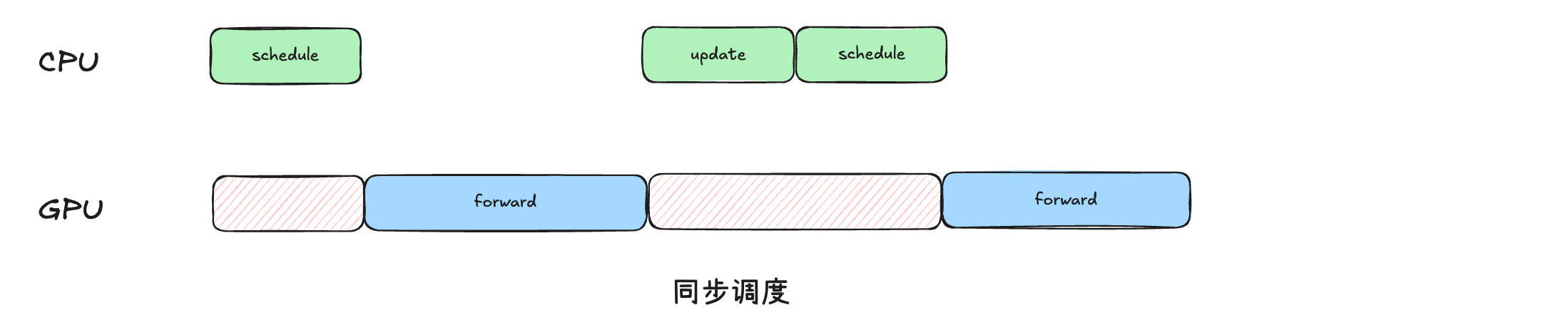 同步调度步骤:
同步调度步骤: