POSTS
vllm 异步调度解析
By ZhongsJie
- 4 minutes read - 1614 words在vllm初始版本中只有一个同步调度策略,在该策略下GPU资源会在调度过程中形成空泡,造成GPU资源的浪费。vllm在v0.10.0版本后提供异步调度策略,并且在后续的迭代中不断加入对于其他特性(例如异步场景下的投机解码)的支持。原始PR内容可查看#19970 Implement Async Scheduling ,当前代码分析基于main branch(735284ed)。
EngineCore处理处理Step逻辑:
def _process_engine_step(self) -> bool:
"""Called only when there are unfinished local requests."""
# Step the engine core.
outputs, model_executed = self.step_fn()
# Put EngineCoreOutputs into the output queue.
for output in outputs.items() if outputs else ():
self.output_queue.put_nowait(output)
# Post-step hook.
self.post_step(model_executed)
return model_executed
同步调度策略#
def step(self) -> tuple[dict[int, EngineCoreOutputs], bool]:
if not self.scheduler.has_requests():
return {}, False
scheduler_output = self.scheduler.schedule()
# 通过FutureWrapper进行异步包装(复用异步调度的部分逻辑, 在同步调度逻辑里面会等待结果返回)
#
future = self.model_executor.execute_model(scheduler_output, non_block=True)
# 用于支持结构化输出等
grammar_output = self.scheduler.get_grammar_bitmask(scheduler_output)
with self.log_error_detail(scheduler_output):
# 同步
model_output = future.result()
if model_output is None:
model_output = self.model_executor.sample_tokens(grammar_output)
# 处理整个过程中abort的请求
self._process_aborts_queue()
engine_core_outputs = self.scheduler.update_from_output(
scheduler_output, model_output
)
return engine_core_outputs, scheduler_output.total_num_scheduled_tokens > 0
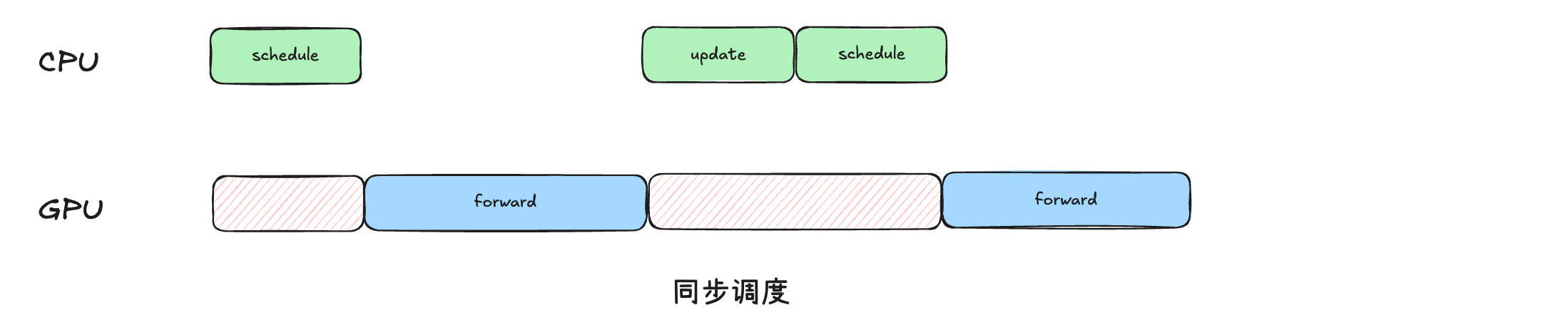 同步调度步骤:
同步调度步骤:
- 调度 -> 调度结果做前向推理 -> 推理后的结果用来采样并更新调度器
核心问题:如果调度器耗时时间长,那么必然会造成GPU资源的浪费。
异步调度策略#
执行步骤#
策略: 优先填充一个batch_queue,在填充过程中会触发execute_model(非阻塞下发)。若无法继续调度且队列非空,则阻塞直到获取对应结果
future.result()。由于batch_queue_size = 2。因此在整个过程中,可以做到调度的同时,仍然有request处于forward过程,从而实现异步调度,增加CPU和GPU的overlap。
def step_with_batch_queue(
self,
) -> tuple[dict[int, EngineCoreOutputs] | None, bool]:
if self.scheduler.has_requests():
scheduler_output = self.scheduler.schedule()
# 非阻塞调用
exec_future = self.model_executor.execute_model(
scheduler_output, non_block=True
)
...
future = cast(Future[ModelRunnerOutput], exec_future)
...
if not deferred_scheduler_output:
batch_queue.appendleft((future, scheduler_output))
if (
model_executed
and len(batch_queue) < self.batch_queue_size
and not batch_queue[-1][0].done()
):
# 优先填充batch_queue,直到queue满,或者没有其他的请求需要调度
return None, True
elif not batch_queue:
return None, False
# 阻塞等待结果
future, scheduler_output = batch_queue.pop()
with self.log_error_detail(scheduler_output):
model_output = future.result()
...
engine_core_outputs = self.scheduler.update_from_output(
scheduler_output, model_output
)
...
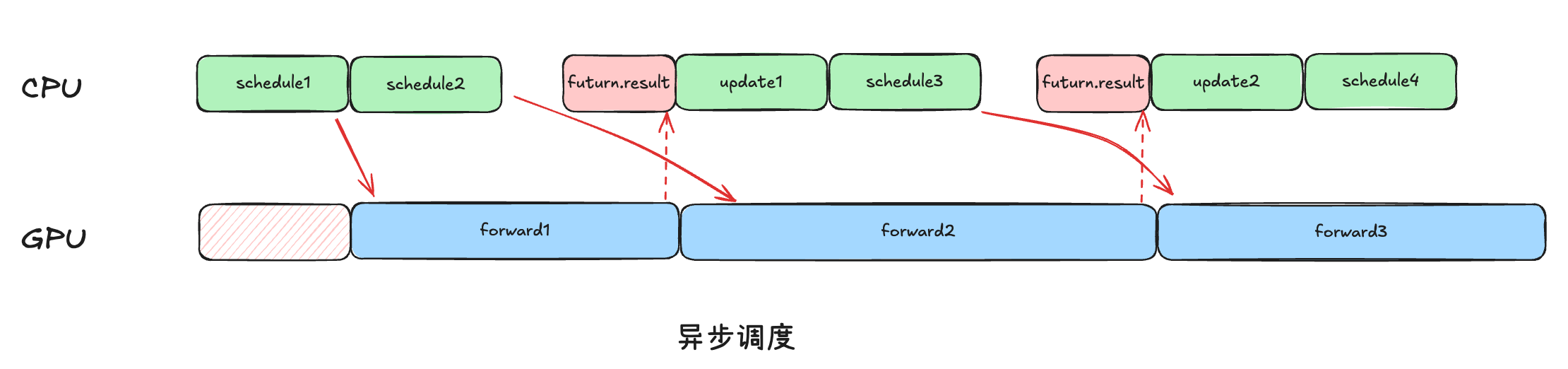
其中异步非阻塞逻辑主要通过FutureWrapper在Executor的collective_rpc(...)中实现,并没有直接修改调度器以及Worker逻辑。
batch_queue 相关配置#
异步调度场景下
batch_queue的大小默认为2,这是由于forward的时间通常远大于调度,设置过大没有太多意义。
self.batch_queue_size = self.model_executor.max_concurrent_batches
self.batch_queue: Optional[deque[tuple[Future[ModelRunnerOutput], SchedulerOutput]]] = None
利用Placeholders进行占位#
由于forward 后的update schedule步骤现在为延迟执行,因此需要提前占位。用于保证async_scheduling 在计算
num_new_tokens的正确性。
class Request:
def __init__(...):
self.num_output_placeholders = 0 # 用于表示在将要生成多少个token信息
class AsyncScheduler(Scheduler):
def _update_after_schedule(...):
# 即将吐出 1个新Token + 投机解码(投机解码spec_token_ids 也会用-1进行占位)
request.num_output_placeholders += 1 + cur_num_spec_tokens
# 后续会更新实际投机解码的Token
request.spec_token_ids = [-1] * self.num_spec_tokens
多流&CUDA event优化#
在异步调度实现过程中引入了CUDA 流和 CUDA event 用于保证数据的正确性,并实现计算与数据传输的重叠,提升 GPU 利用率。
class GPUModelRunner(...):
...
self.async_output_copy_stream: torch.cuda.Stream | None = None
...
self.prepare_inputs_event: torch.Event | None = None
if self.use_async_scheduling:
self.async_output_copy_stream = torch.cuda.Stream()
self.prepare_inputs_event = torch.Event()
class AsyncGPUModelRunnerOutput(...):
...
self.async_copy_ready_event = torch.Event()
async_output_copy_stream:用于AsyncModelRunnerOutput处理采样token_ids(gpu->cpu)的to操作,用于提升GPU利用率。prepare_inputs_event: 在每次prepare input 过程中复用CPU tensor的时候,会触发一次self.prepare_inputs_event.synchronize()。- CPU可能会在GPU还在使用输入张量时就准备下一个批次的输入,因此这里的
synchronize用于避免CPU覆盖或重用GPU仍在访问的张量。
- CPU可能会在GPU还在使用输入张量时就准备下一个批次的输入,因此这里的
async_copy_ready_event: 成功将_sampled_token_ids以及_logprobs_tensors从GPU同步到CPU后记录一个event,当get_output的时候触发synchronize,保证结果正常计算完成。
Sglang有类似实现:Zero-Overhead Batch Scheduler 零开销批处理调度器