Below you will find pages that utilize the taxonomy term “Ai”
📎Posts
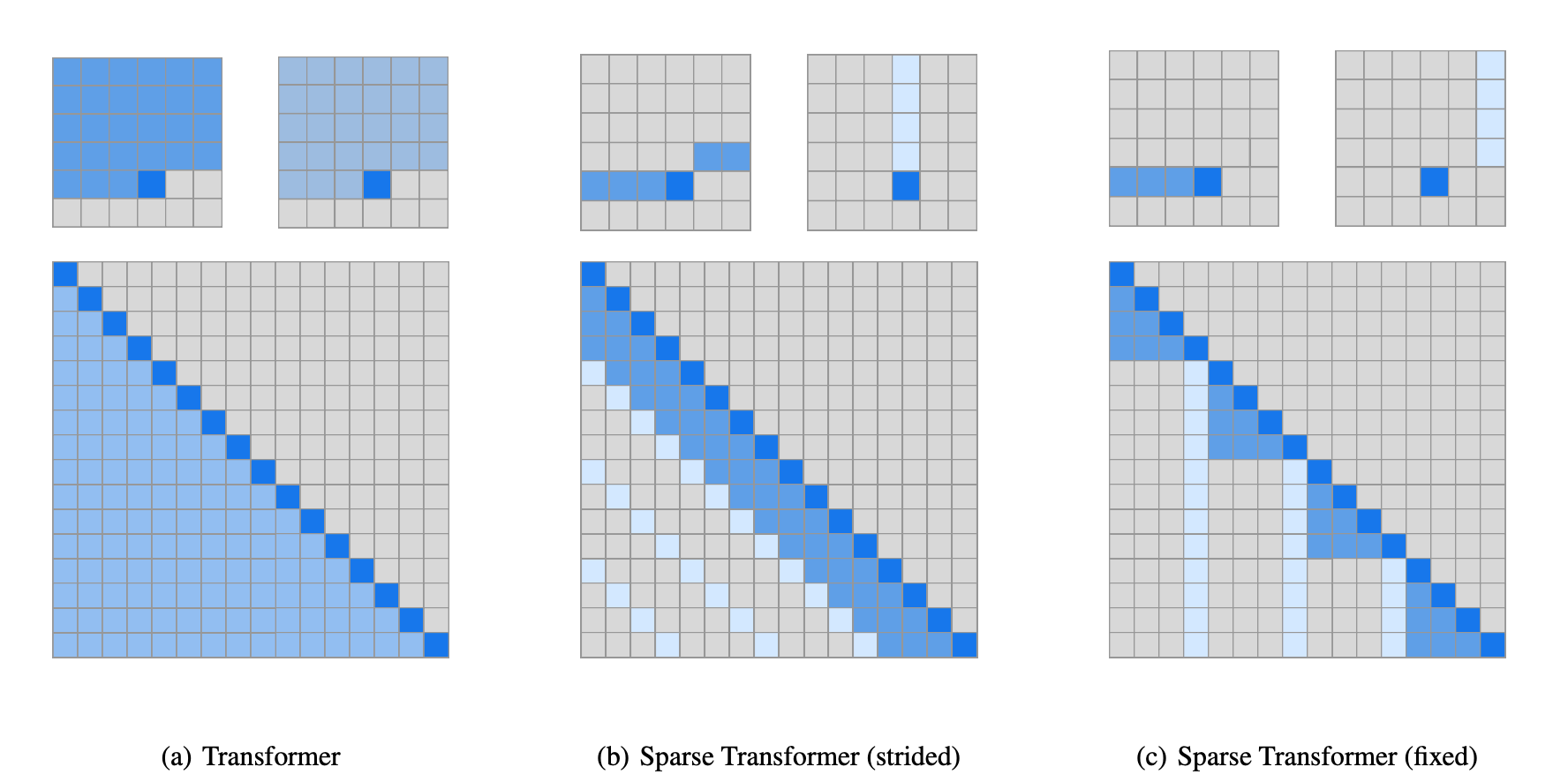
DSA(Deepseek Sparse Attention)
稀疏注意力#
复杂度瓶颈#
Transformer 架构的核心是缩放点积注意力 (Scaled Dot-Product Attention):
$$o_i = \sum_{j=1}^{n} \alpha_{ij} \cdot v_j, \quad \alpha_{ij} = \operatorname{softmax}\left(\frac{q_i^T k_j}{\sqrt{d_k}}\right)_j$$其中 $Q, K, V \in \mathbb{R}^{n \times d}$ 分别是查询、键、值矩阵。
$QK^T$ 矩阵的形状为 $n \times n$,计算复杂度 $O(n^2 d)$,空间复杂度 $O(n^2)$。对于长序列($n=128\text{K}$,$d=4096$,FP16),仅注意力矩阵就需要 $128\text{K} \times 128\text{K} \times 2\text{B} \approx 32\text{ GB}$ 显存——单张 GPU 无法承受。
注意力矩阵的稀疏性来源于一个直觉观察:并非所有 token 对都同等重要。大多数 token 对之间的注意力权重接近零,仅有少数 token 对承载了主要的信息交互。
这种稀疏性有两层含义:
- 自然的局部性:相邻 token 之间的依赖远强于远距离 token
- 内容相关性:语义相关的 token 即使距离远也需要交互
稀疏注意力方法试图在信息完整性和计算效率之间寻找最优平衡。
📎Posts
Split QKV + RMSNorm + RoPE 融合算子
源代码:
vllm-ascend/vllm_ascend/ops/triton/linearnorm/split_qkv_rmsnorm_rope.py
背景#
问题:内存墙#
LLM 推理(尤其是 decode 阶段)是典型的 memory-bound 场景。每一次算子调用都是一次「从 Global Memory 搬数据到片上 → 计算 → 搬回 Global Memory」的循环。如果不融合,Split QKV → RMSNorm → RoPE 这三个步骤各自独立执行:
非融合流程:
hidden_states ──[load]──> Split Q,K,V ──[store]──> q_in, k_in, v_in
q_in ──[load]──> RMSNorm ──[store]──> q_normed
k_in ──[load]──> RMSNorm ──[store]──> k_normed
q_normed ──[load]──> RoPE ──[store]──> q_out
k_normed ──[load]──> RoPE ──[store]──> k_out
每一次 load/store 都是一次 GM ↔ UB 的数据搬运。数据在总线上反复进出,但实际的计算量(几个乘加 + 一个开方)极小——这就是 memory-bandwidth bottleneck。
📎Posts
Worker
vLLM 分布式通信
class WorkerProc:
"""Wrapper that runs one Worker in a separate process."""
READY_STR = "READY"
rpc_broadcast_mq: MessageQueue | None
worker_response_mq: MessageQueue | None
@instrument(span_name="Worker init")
def __init__(...):
self.rank = rank
wrapper = WorkerWrapperBase(rpc_rank=local_rank, global_rank=rank)
...
wrapper.init_worker(all_kwargs)
self.worker = wrapper
...
self.worker.init_device()
if envs.VLLM_ELASTIC_EP_SCALE_UP_LAUNCH:
self.worker.elastic_ep_execute("load_model")
else:
self.worker.load_model()
。。
Worker init_device#
worker的init_device函数负责初始化设备的相关信息
- 根据当前worker的rank找到它所属的device,将它绑到指定的卡上,以及清空该device的显存,获取该device的显存大小等
- 对当前的worker做分布式环境初始化,也就是初始化当前worker的各种进程组(如模型并行、流水线并行、数据并行等)
- 构造当前worker的GPUModelRunner对象。维护着模型权重分片,还维护模型运行过程中所需要的一些数据结构,比如kv cache等,负责模型权重的加载(load_model),以及实际的推理执行过程等逻辑。
@instrument(span_name="Init device")
def init_device(self):
if self.device_config.device_type == "cuda":
...
# Ray 会设置 NCCL_ASYNC_ERROR_HANDLING,但这个环境变量会导致 CUDA graph
# 构建时出现异常。CUDA graph 需要同步执行,而该变量会引入异步错误处理,
# 两者可能引起冲突。
os.environ.pop("NCCL_ASYNC_ERROR_HANDLING", None)
...
# - Ray/external_launcher 场景:这些分布式执行器自己管理GPU映射
# - 多节点场景(nnodes_within_dp > 1):每个节点有独立的GPU集合,映射逻辑不同
# - Ray作为DP后端:Ray的resource pool处理GPU分配
if (
parallel_config.distributed_executor_backend
not in ("ray", "external_launcher")
and parallel_config.data_parallel_backend != "ray"
and parallel_config.nnodes_within_dp == 1 # 单节点场景
):
# local DP rank 表示在当前节点内的数据并行编号,而 global rank 可能
# 跨节点。在单节点场景下,GPU映射只看节点内的local rank。
dp_local_rank = self.parallel_config.data_parallel_rank_local
if dp_local_rank is None:
dp_local_rank = self.parallel_config.data_parallel_index
# DP副本 0 (dp_local_rank=0)
# original_local_rank=0 → GPU 0 + 0×2 = GPU 0
# original_local_rank=0 → GPU 0 + 1×2 = GPU 2 ← 偏移
# 偏移是为了计算出实际的rank信息,后续用来初始化device
self.local_rank += dp_local_rank * tp_pp_world_size
。。
self.device = torch.device(f"cuda:{self.local_rank}")
# PyTorch的设备API演进:从 torch.cuda.set_device() 到
# torch.accelerator.set_device_index()。 后续可以不用再手动指定,
torch.accelerator.set_device_index(self.device)
...
# 初始化分布式推理所需的所有环境,包括通信组信息
# 优先于内存快照处理逻辑,NCCL在初始化会分配内部缓存区,提前初始化用于保证显存计算的准确性
init_worker_distributed_environment(
self.vllm_config,
self.rank,
self.distributed_init_method,
self.local_rank,
current_platform.dist_backend,
)
# 1. gc.collect() 回收Python层的垃圾对象,释放可能的GPU引用
# 2. empty_cache() 释放PyTorch缓存的显存(包括NCCL缓冲区)
# 得到一个"干净"的显存状态,作为基准线
gc.collect()
torch.accelerator.empty_cache()
# 用于后续计算 KV cache 可用显存。
# init_snapshot 记录当前可用显存,request_memory 根据模型配置
# 计算需要预留的 KV cache 大小。
self.init_snapshot = init_snapshot = MemorySnapshot(device=self.device)
self.requested_memory = request_memory(init_snapshot, self.cache_config)
# 最后初始化modelrunner,需要依赖设备、分布式通信环境,同时通过快照可以计算出可以分配的kv cache显存大小
if self.use_v2_model_runner:
...
self.model_runner: GPUModelRunner = GPUModelRunnerV2( # type: ignore
self.vllm_config, self.device
)
else:
...
self.model_runner = GPUModelRunnerV1(self.vllm_config, self.device)
...
init_worker_distributed_environment#
负责初始化分布式推理所需的所有环境组件